[AI] Machine Learning1
기계 학습의 정의와 그 종류에 대해서 알아본다.
이번 포스팅에서는 기계 학습의 정의와 그 종류에 대해서 살펴본다.
1. 기계학습
인공지능은 사람이 사람과 같은 지능으로 기계가 스스로 학습하고 추론하도록 하는 기술이다. 기계 학습, 언어 처리, 컴퓨터 비전, 로보틱스 등의 분야를 포함한다.
기계 학습은 인공지능의 한 분야로, game tree의 alpha-beta pruning 창시자인 Arthur Samuel은 기계 학습을 직접적으로 프로그래밍하지 않고 컴퓨터가 스스로 배울 수 있는 능력을 다루는 학문으로 정의하였다. 이처럼 기계 학습은 수많은 경험 혹은 경험으로 얻은 데이터로부터 알고리즘을 생성하고 이를 개선할 수 있다고 가정한다.
1-1. 인공지능 모델 정의하기
잘 정의된 인공지능은 T(Task), P(Performance metric), E(Experience, data)가 완벽하게 정의되어 있어야 한다. T는 학습시키고자 하는 작업, P는 작업의 성능을 평가할 수 있는 기준, E는 학습 데이터를 말한다.
1-2. 전통적인 프로그래밍과의 차이

전통적인 프로그래밍은 코드와 input이 주어질 때, 컴퓨터는 프로그램에 정의된 순서대로 연산을 수행하고 그에 대한 output을 출력한다.

하지만 기계 학습은 input와 그에 따른 output을 쌍으로 모아서 컴퓨터에게 제공한다. 그러면 컴퓨터는 input에 따른 output을 출력하는 프로그램을 반환한다. 해당 프로그램의 전체적인 구조는 이미 정해져 있고 특정 부분만 input과 output에 의해 변형되어 나온다.
예를 영단어의 스펠링을 체크하는 프로그램을 작성한다고 하자. 다양한 경우의 수와 가능성이 있기에 전통적인 프로그래밍 방식으로는 해당 프로그램을 만들기 어렵다. 하지만 기계 학습의 경우 (오타가 있는 단어, 오타가 수정된 단어)와 같이 (input, output) 쌍을 구성해서 컴퓨터에게 전달해주기만 하면 된다. 이처럼 전통 프로그래밍에서는 해결하기 어려운 몇몇 문제들은 기계 학습을 통하면 쉽게 해결할 수 있다.
2. 일반화
많은 사람들이 기계 학습의 목표를 주어진 데이터만을 학습하는 것으로 생각한다. 하지만 기계 학습의 진짜 목표는 주어진 데이터를 학습하여 특정 패턴을 배우도록 하는 것이다. 특정 패턴을 통해 학습 데이터 밖의 데이터가 주어졌을 때에도 적절한 추론이 가능하도록 해야 한다. 이러한 능력을 일반화(generalization)라고 한다.
예를 들어, 어린 아이가 여러 종류의 나무를 보고 공통된 특징을 파악해 ‘나무’라는 개념으로 추상화한다. 그러면 새로운 나무를 접하게 되더라도 아이는 ‘나무’라고 추론할 수 있다.
이처럼 학습 데이터를 완벽히 이해하면 반대로 학습 데이터를 생성하는 것도 가능하다. 실제로 생성형 모델(GAN)이 이러한 점을 이용하여 제작되었다.
2-1. No Free Lunch
매번 새로운 데이터를 얻고, 새로운 task에 대해 학습을 할 때에는 최적의 알고리즘을 찾는 과정이 필요하다. 모든 상황에 대해 항상 좋은 학습 결과를 내는 알고리즘은 없다.
3. 학습의 종류
학습의 종류는 학습에 사용하는 데이터의 특성에 따라 크게 지도 학습(supervised learning), 비지도 학습(unsupervised learning), semi-supervised learning, reinforcement learning (강화학습)으로 나눌 수 있다.
3-1. 지도 학습 (Supervised Learning)
지도 학습은 입력 데이터와 정답이 명시적으로 주어진 상태에서 모델을 학습시키는 방법이다. 정답이 범주형으로 이루어진 분류(Classification)와 실수의 범위의 정답을 예측하는 회귀(Regression)가 이 학습 방식에 해당된다.
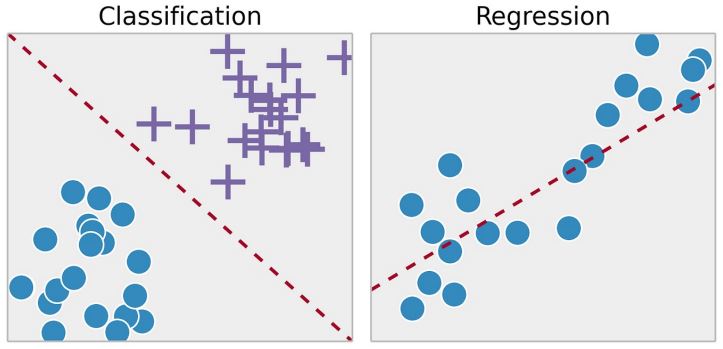
- 분류(Classification) : 이메일 스팸 분류, 손글씨 인식
- 회귀(Regression) : 주식 가격 예측, 기온 예측
사용 가능한 알고리즘으로는 결정 트리(Decision Tree), k-NN, 로지스틱 회귀 등이 있다.
3-2. 비지도 학습 (Unsupervised Learning)
비지도 학습은 정답 없이 입력 데이터만으로 모델이 데이터 내의 패턴을 찾도록 학습시키는 방법이다. 군집화(Clustering), 아웃라이어 감지(anomaly detection) 등이 이 학습 방식에 해당된다.
사용 가능한 알고리즘으로는 k-Means, DBSCAN 등이 있다.
3-3. Semi-supervised Learning
일부의 데이터는 지도 학습으로, 또 일부의 데이터는 비지도 학습으로 섞어서 모델을 학습시키는 방법을 semi-supervised learning이라 한다. 이 학습법은 라벨링에 많은 시간이 소요되는 지도 학습을 개선한 학습 방법으로, 특정 클래스에 대한 데이터만을 지도 학습으로 주는 PU learning(Positive and Unlabeled) 방식과 모든 클래스에 대해 일부 지도 학습 데이터를 포함하는 LU learning(small set of Labeled and large set of Unlabeled) 방식이 있다.
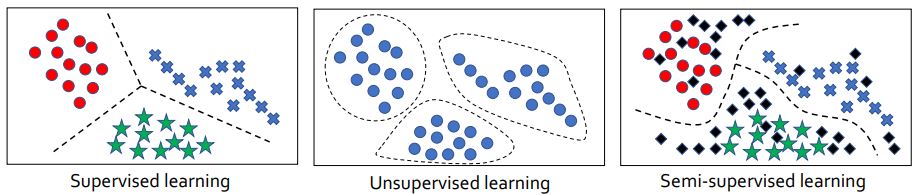
Semi-supervised Learning 방법은 라벨링된 데이터를 바탕으로 예측된 decision boundary에 비지도 학습 데이터로 정확성을 추가한다. 그 결과, 더 높은 성능의 classification이 가능하다.
3-4. Reinforcement Learning (강화학습)
강화학습은 데이터 대신에 환경이 주어진다. Agent가 환경과 상호작용하면서 action에 따른 평가(reward, 보상)를 바탕으로 학습하게 된다. 하지만 여러 action에 대한 평가(reward)를 나중에 한번에 받게 되므로, 앞서 순차적으로 했던 수많은 action에 대해 일일히 평가를 분배하는 것이 쉽지 않다. 따라서 강화학습은 다른 학습 방법보다 학습 시간이 더 길고 학습 난이도가 더 높은 편이다.
참고
본 포스팅은 LG Aimers 강좌 중 서울대학교 김건희 교수님의 ‘Machine Learning 개론’에서 학습한 내용을 정리한다.