[AI] Machine Learning2
기계 학습 성능에 영향을 주는 요소와 초거대 언어모델에 대해 소개한다.
1. 학습 시 고려사항
기계 학습의 목표인 일반화는 오차를 구성하는 편향(bias), 분산(variance)과 밀접하게 연관되어 있다. 최적화된 모델을 선택하기 위해서는 이 둘의 trade-off 관계를 이해할 필요가 있다. 그리고 학습 정도에 따른 underfitting과 overfitting에 대해서도 설명한다.
기계 학습을 진행하기 위해서는 사용할 모델 클래스(hyper class, ex. 선형 모델)와 파라미터(parameter)를 먼저 정의해야 한다. 모델은 학습 데이터 s에 대해 잘 작동하는 파라미터 W, b를 찾게 되는데, 이를 parameter estimation이라 한다.
해당 모델이 잘 동작되는지 평가하기 위해서 손실 함수(Loss function)를 사용하는데, 손실 함수는 실제와 예측값이 차이가 날 수록 큰 값을 반환하도록 정의된다.
결국 모델의 학습은 손실 함수를 최소화하는 문제로 변형될 수 있다.
지도 학습에서의 손실함수
- 분류(Classification) : 0/1 loss function
- 회귀(regression) : squared loss function
1-1. Generalization Error(일반화 에러)
모든 데이터를 가지고 있는 이상적인 데이터 셋을 universal dataset이라고 하자. 이 universal 데이터셋으로 학습을 하면 우리는 true distribution을 생성할 수 있다. 하지만 이 universal 데이터셋은 구할 수 없기에 우리는 일부를 샘플링한 train set과 test set으로 대신 학습과 평가를 한다.
일반화 능력에 대한 에러를 generalization error, train 데이터셋에 대한 에러를 training error 그리고 테스트 데이터셋에 대한 에러를 test error라고 하자. 그러면 underfitting과 overfitting에 대한 정의를 아래와 같이 할 수 있다.
- Underfitting : Generalization error < Training error ( =training error가 충분히 낮지 않은 상황)
- Overfitting : Generalization error > Training error ( =training error와 test error간의 차이가 매우 큰 상황)
Underfitting의 경우, 모델이 학습이 아예 안된 상황이기에 Overfitting보다 더 좋지 않은 상황이다.
1-2. Model Capacity
현재 7개의 데이터가 있고, 해당 데이터에 대해 모델을 생성한다고 하자.
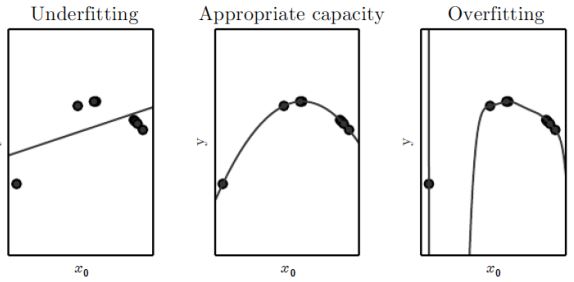
왼쪽 이미지는 linear 함수로 해당 데이터를 학습하는 상황이다. 아무리 여러번 학습을 수행해도 하나의 선으로는 데이터에 대한 일반화가 어렵다. 따라서 이 경우는 Underfitting이라고 할 수 있다.
반대로 데이터를 9차 함수로 표현한다고 하자. 이 경우에는 오른쪽 그림과 같이 모든 데이터를 정확히 지나가는 모델을 그릴 수 있을 것이다. 하지만 이 경우에 여러번의 학습이 수행되면 데이터에 경향에 과하게 맞추기 위해, 데이터가 관측되지 않은 곳에 대해서는 급격한 기울기 변화가 일어나는 overfitting이 일어날 수 있다.
그렇기에 적절한 일반화가 이루어지기 위해서는 중간 이미지와 같이 모델의 차수를 너무 작지도, 너무 크지도 않은 수로 설정해야 한다.
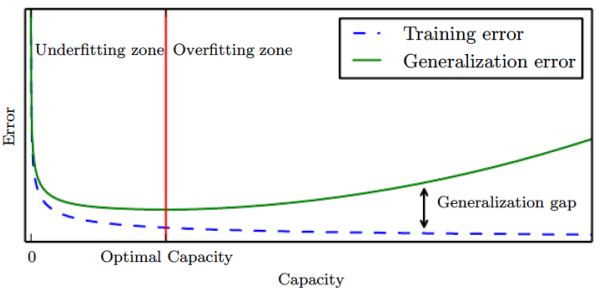
일반적으로 모델의 차수가 클수록, training error는 줄어들지만 generalization error과의 차이는 커진다. 따라서 우리는 training error가 충분히 낮으면서 generallization error와 차이가 작은 빨간선 지점의 모델 차수를 찾아야 한다.
Occam의 면도날 법칙?
현상을 설명할 수 있는 모델이 여러개일 때, 경험적으로 가장 간단한 모델이 정답인 경향이 있다.
1-3. Regularization(규제)
앞서 모델의 학습은 손실 함수를 최소화하는 문제로 변형될 수 있다고 말했었다. 하지만 overfitting에 빠지지 않기 위해서는 모델의 capacity 또한 동시에 최소화해야 한다. 이럴 때 사용할 수 있는 것이 regularization이다. 모델의 capacity가 증가할수록 값이 커지는 regularization term을 사용한다.
\[J(w) = (error) + \lambda w^Tw\]위의 식을 사용하면 Loss뿐만 아니라 모델의 capacity 또한 고려해서 최소화하는 목적함수를 생성할 수 있다. Hyperparameter인 $\lambda$를 0으로 주면 손실함수만으로 최소화를 고려하고 $\lambda$를 크게하면 모델 capacity의 영향력을 더 크게 최소화에 반영하겠다는 의미이다.
Hyperparameter (=tuning parameter)?
모델 학습시에 연구자/개발자가 제공하는 파라미터으로, 보통 Cross-Validation(교차 검증) 과정을 통해서 결정하게 된다.
regularization는 training error가 아닌 일반화 에러를 낮추는 것을 목표로 한다.
1-4. 편향과 분산
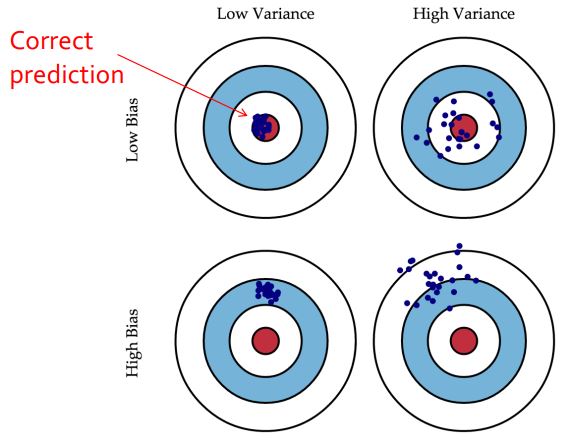
편향과 분산은 양궁 과녁으로 쉽게 이해할 수 있다. 모델의 목표는 중앙 과녁을 맞추는 것이 목표이다. 하지만 편향이 높으면 원래 목표 지점으로부터 예측이 많이 멀어지게 되고, 분산이 높으면 어떤 때는 잘 예측하고 어떤 때에는 잘못된 결과를 내듯이 예측 결과의 정답률이 불안정하다. 따라서 좋은 모델은 안정적이게 중앙과녁 중심으로 예측해야 한다.
편향이 높다는 것은 정답을 근처로 예측하지 못하는 상황이므로 underfitting을 포함한다고 해석할 수 있다. 따라서 편향은 모델의 복잡성을 높여 낮출 수 있다.
반대로 분산이 높다는 것은 모델이 불안정하는 것을 의미하므로 overfitting으로 해석할 수 있다. 따라서 분산은 학습 데이터 수를 늘려 낮출 수 있다.
하지만 편향과 분산은 서로 trade off 관계이며 아래 수식을 만족한다.
\[test-error = Bias + Variance\]- bias는 예측의 평균 값과 실제 값 사이의 평균
- variance는 예측 평균값과 예측 값 사이의 평균
적절히 낮은 값의 편향과 분산를 가지도록 모델을 학습해야 한다.
1-5. 모델 학습
아래와 같은 과정을 통해서 모델을 잘 학습시킬 수 있다.
- training error를 최소화는 모델을 찾는다.
- 일부러 모델을 overfitting 시킨다. overfitting이 된다는 건 반대로 학습이 잘되는 모델임을 의미하기 때문이다.
- training error와 validation/test error간의 차가 작아지도록 학습시킨다.
- 오버 피팅과 모델의 용량 사이의 상관관계를 이용한다.
- 따라서 최적의 capacity 모델을 찾아 사용하거나 높은 capacity에 regularization을 사용한다.
2. 초거대 언어 모델
OpenAI사의 GPT시리즈와 같은 모델은 수십억개의 이상의 파라미터로 이루어져 있다. 이러한 언어 모델을 초거대 언어 모델(LLM, Large Language Model)이라고 한다.
2-1.GPT(Generative Pretrained Transformer)
OpenAI사는 GPT3부터 연구 결과를 비공개하고 있다. GPT는 언어 기반의 General purpose 알고리즘으로 언어에 대한 이해가 뛰어나다. 하지만 언어를 이해한다고해서 응답에 대한 전문적인 답변을 내놓는 것은 아니다. 언어 모델의 단점으로 꼽히는 환각(hallucination)이 GPT에서도 나타나고 있다.
환각(Hallucination)?
언어 모델이 거짓된 정보를 만들어내는 것이다. 예를 들어, ‘콜롬버스가 2015년에 미국에서 무슨 일을 했어?’라고 물어봤을 때, 인공지능이 이야기를 만들어서 마치 사실인 마냥 대답해주는 것이 환각에 해당된다.
GPT3를 기반으로 사용자의 지시에 유용하면서 안전한 답을 할 수 있도록 학습한 모델을 instructGPT라고 한다. instructGPT는 RLHF(Reinforcement Learning Human Feedback, 인간 피드백 강화학습) 기술을 사용하여 사용자의 의도에 부합하는 응답을 할 수 있도록 학습한다.
또한 응답을 제작할 때, context length를 사용하여 문맥에 맞는 응답을 제공하고자 노력하고 있다.
2-2. RLHF
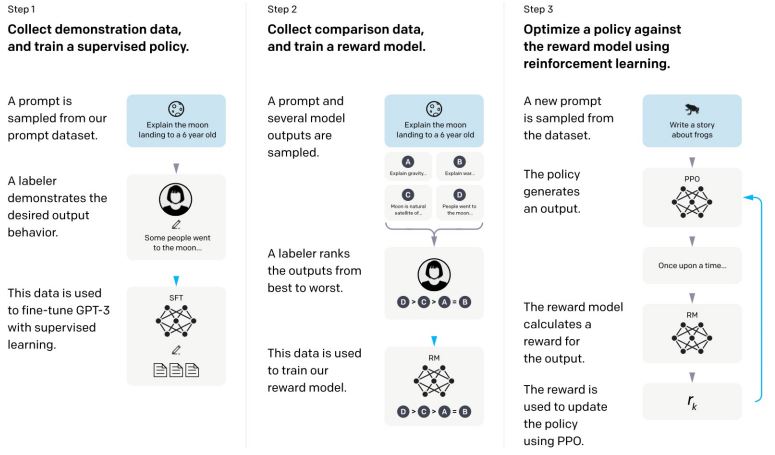
OpenAI에서 공개한 기술의 설명에 따르면, instructGPT는 3가지 스텝을 통해 학습된다. 첫번째 단계는 SFT(Supervised Fine Tuning)이다. 질문과 사람이 직접 작성한 응답의 쌍을 지도학습을 통해 학습을 시킨다.
학습 후에 이어서 두 번째 단계인 reward model을 학습한다. 첫 단계에서 학습시킨 모델로 하나의 질문에 대해 여러 개의 응답을 만든다. 그리고 사람이 이 응답들을 선호도에 따라 순위를 매기게 한다. 이 데이터들을 reward model에 학습한다.
마지막 세 번째 단계에서는 강화학습 PPO를 통해서 질문에 대한 응답 정책을 생성한다. 정책을 통해 응답을 생성하고 앞 단계의 reward model을 사용해 해당 응답에 대한 reward를 예측한다. 그리고 예측된 reward를 바탕으로 정책을 업데이트한다.
PPO(Proximal Policy Optimization)
OpenAI사에서 개발한 강화학습 알고리즘으로, 기존의 강화학습보다 안정성과 효율성이 높다고 평가받는다.
2-3. ChatGPT
제작된 instructGPT는 초기에 API 형태로 사용되었다. ChatGPT는 instructGPT에 대화형 환경을 제공하여 사용자와의 상호작용을 용이하도록 했다. 그렇게 함으로써 개발자나 연구자가 아니더라도 instructGPT 모델을 사용할 수 있게 되었고, 이는 MAU(Monthly Active User, 월간 활성 사용자 수)를 두달만에 1억명에 도달하는 빠른 성장으로 이어진다.
2-4. 다른 초거대 언어 모델의 예시
- Anthropic사의 Claude
- Google사의 Bard, PaLM
- Meta사의 OPT, LLaMa (오픈 소스) Meta사의 LLaMa 이후로 이를 활용한 self-instruct tuning한 모델인 Alphaca, Vicuna들이 개발되고 있다.
참고
본 포스팅은 LG Aimers 강좌 중 서울대학교 김건희 교수님의 ‘Machine Learning 개론’에서 학습한 내용을 정리한다.